Physical Intelligence π0.7: The Generalist Robot Brain That Actually Generalizes
Highlights of AI News for April 13 - 19 2026
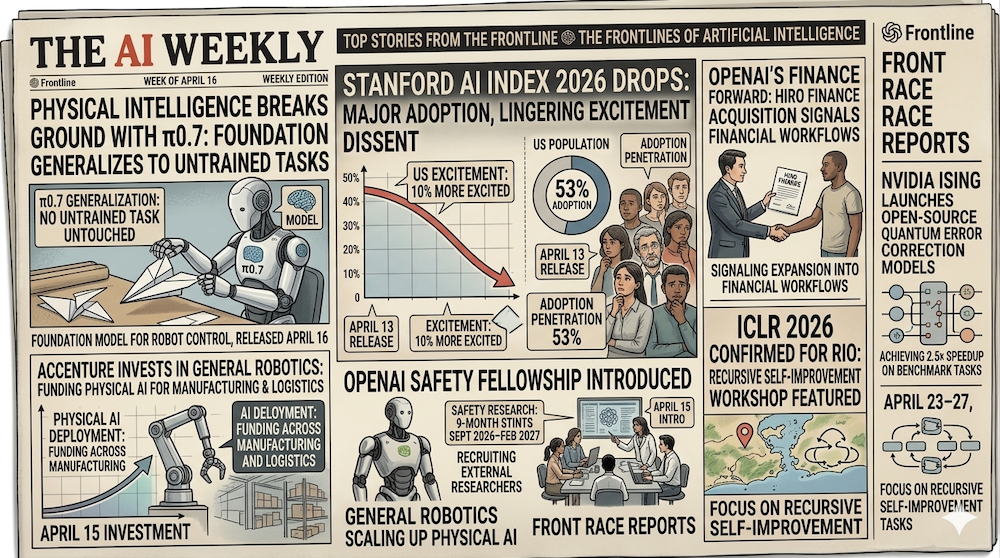
Week in Review | Two frontier model releases landed on the same Thursday: Physical Intelligence's π0.7 — a generalist robot policy showing compositional generalization — and Anthropic's Claude Opus 4.7, which jumps 13% on coding benchmarks and nearly doubles visual-acuity scores over 4.6. NVIDIA launched Ising on April 14, the first open AI models for quantum error-correction decoding and calibration. The Stanford AI Index 2026 dropped April 13 with a sobering U.S. adoption figure (28.3%, ranked 24th globally) and a stubborn sentiment gap. OpenAI acquired Hiro Finance on April 13 and introduced a Safety Fellowship on April 15. Accenture invested in General Robotics the same day, and Boston Dynamics integrated Gemini Robotics-ER 1.6 into Spot. Cerebras filed for an IPO on April 18. ICLR 2026 opens Thursday in Rio.
Watch our video: on Youtube or Rumble
Physical Intelligence π0.7: Compositional Generalization for Robots
On April 16, Physical Intelligence (PI) released π0.7, the successor to last fall's π₀ generalist policy. The headline is compositional generalization: the model recombines skills learned in distinct contexts to handle tasks it was never explicitly trained on. PI's own example is deliberately odd — π0.7 synthesized a "push" primitive and a "bottle placement" primitive (two unrelated training episodes) into an attempt at putting a sweet potato in an air fryer, apparently pulling the procedural structure from web-scale pretraining rather than any teleoperated demonstration of the task.
The model is a single unified policy — no per-task fine-tunes, no skill libraries — and PI emphasizes that the important delta from π₀ is not raw success rate but the multimodal prompting framework it now supports. π0.7 accepts language coaching for step-by-step verbal instruction, visual subgoals that show what an intermediate state should look like, and strategy metadata that biases the model toward speed, quality, or a specific control mode. Where π₀ was a generalist trained to imitate; π0.7 is a generalist you can steer.
Benchmarks on in-distribution tasks are near ceiling — 100% on t-shirt and shorts folding, 100% on espresso making, 100% on box building. The more interesting number is cross-embodiment: a bimanual UR5e industrial arm folded shirts at a success rate that "matches the zero-shot success rate of expert teleoperators," without a single UR5e folding demonstration in the training set. PI is careful about framing: the paper calls these "early signs" of generalization rather than production capability, and notes that complex multi-step tasks still require step-by-step coaching rather than single-command execution.
This lands directly in W16's theme. Our trend tutorial 4D Gaussian Frontier and our primers on 4D Gaussian Splatting and video-to-3D understanding argue that temporal geometry is non-negotiable for embodied agents. π0.7 is the policy side of that thesis: given a world model, you still need a control stack that composes skills. The companion notebooks walk through the perception half.
Why it matters: Foundation models for robotics went from hypothesis to consensus between π₀ (October 2025) and π0.7 (April 2026). The robotics stack is now compressible to: foundation policy + multimodal prompting + light per-robot adaptation. That's the same abstraction shift Transformers made for NLP — and it arrives roughly on the timeline Sergey Levine's group has been publicly forecasting for two years.
Anthropic Releases Claude Opus 4.7
Anthropic shipped Claude Opus 4.7 on April 16 — the same day as π0.7, coincidentally — with gains concentrated in three areas: software engineering on long-running tasks, higher-resolution vision, and agentic reasoning. Pricing is unchanged at 25/M output tokens, which is the more important product signal: Anthropic is delivering capability gains within the existing price envelope rather than segmenting up-market.
The benchmark deltas are substantial. Opus 4.7 posts a 13% improvement over 4.6 on a 93-task internal coding benchmark, and resolves roughly 3× as many production-grade tasks on Rakuten-SWE-Bench. The vision upgrade is the most quantitative: 98.5% on visual-acuity benchmarks versus 54.5% for 4.6, with the model now accepting images up to ~3.75 megapixels (2,576 pixels on long edge), more than 3× the resolution of prior Claude models. That directly enables technical-diagram interpretation — circuit schematics, chemical structures, architectural drawings — at a level that prior generations truncated.
The positioning is instructive. Anthropic explicitly notes that Opus 4.7 is "less broadly capable" than the Claude Mythos Preview (the frontier model that's been under safety review since the March leak controversy), but outperforms 4.6 on most benchmarks with similar safety properties. That's the cadence: Mythos is the research frontier, Opus 4.7 is the production workhorse. Customers get the incremental wins; the safety case stays intact.
Why it matters: The frontier lab cadence has bifurcated. Monthly-to-quarterly releases like Opus 4.7 deliver production gains within stable pricing; annual "flagship" releases (Mythos, GPT-5, Gemini Ultra) reset the frontier. That's more like Apple's M-series silicon than like GPT-3 → GPT-4. For practitioners, the takeaway: don't wait for the flagship; the point release in your price tier is usually the right target.
Stanford AI Index 2026: Adoption Lags, Sentiment Fractures
The Stanford AI Index 2026, released April 13, landed with a headline that surprised many: the U.S. ranks 24th globally in generative AI adoption, at 28.3%. The 53% figure widely circulated in coverage is the global three-year penetration rate — not a U.S. number. The U.S. is below the worldwide average.
The sentiment picture is equally non-linear. 59% of Americans now say they feel optimistic about AI's benefits (up seven points year-over-year), but 52% also say they feel nervous about the technology (up two points). That's not a contradiction — it's anxious optimism, and it's the defining mood of this cohort. The deeper gap is between the public and experts: 73% of AI experts expect positive net impact on jobs, compared to just 23% of the public. A 50-point gap on the most consequential AI question is politically combustible.
Trust in government to regulate AI is where the U.S. most clearly diverges: 31% — the lowest of any country the Index tracks. Contrast that with the four-in-five figure for student adoption: over 80% of U.S. high school and college students now use AI for schoolwork. A generation is adopting the technology fluently while simultaneously believing their government is incapable of governing it. That's a regulatory tinderbox — and it's why every state-level AI bill now faces scrutiny from both sides.
Why it matters: The U.S. is in a structurally unusual position — high per-capita compute and frontier-model output, but mid-pack consumer adoption and rock-bottom regulatory trust. That distributes adoption friction differently than a top-down EU-style framework handles. Expect federal preemption debates to accelerate as the state patchwork thickens and the public's trust gap stays sticky.
OpenAI Acquires Hiro Finance: Vertical Expansion Continues
On April 13, OpenAI acquired Hiro Finance, a personal-finance AI startup founded in 2024 by Ethan Bloch. The acquisition amount was undisclosed. Hiro had launched publicly roughly five months before the deal — an unusually quick exit, signalling that OpenAI valued the team and data integrations more than any runway or revenue the company had accumulated.
This continues the expansion playbook W15 flagged with the January ChatGPT ad pilot and the April 9 $100B ad-revenue target. Hiro brings domain-expertise tuning for budgeting, tax optimization, and investment workflows, plus the financial-institution data integrations that are expensive to reproduce and slow to license. Acquisition is faster than build, especially when the target's technical moat is relationships with regulated counterparties rather than proprietary algorithms.
The strategic read-through: OpenAI is not building a single assistant — it's assembling verticalized workflows behind one consumer brand. Financial OS is one front; education, health-adjacent consumer productivity, and creative tooling are likely the next. Expect at least two more vertical acquisitions in 2H 2026.
Why it matters: The market premium on AI-native consumer fintech just compressed. If OpenAI is acquiring five-month-old startups for domain integrations, the hurdle for building-to-exit is now a scarce moat (exclusive data, regulated relationships) within a domain OpenAI plausibly wants. Founders building generalist consumer AI products face tougher differentiation; those building in narrow regulated verticals just got a clearer acquirer landscape.
NVIDIA Ising: Open AI Models for Quantum Error Correction
On April 14, NVIDIA launched Ising — a family of open AI models for quantum-processor calibration and quantum error-correction decoding. The headline numbers are precise: Ising Decoding runs 2.5× faster and 3× more accurate than pyMatching, the current open-source industry standard for surface-code decoding. Ising Calibration, a vision-language model, shortens calibration runs from days to hours.
The release has two components. Ising Calibration is a VLM that reads quantum-processor telemetry and produces calibration parameters directly — NVIDIA calls it "the world's best AI-based quantum processor calibration." Ising Decoding ships two 3D CNN variants, one tuned for latency, one tuned for accuracy. Both are released on GitHub and Hugging Face alongside a "cookbook of quantum computing workflows and training data" — the license is not explicitly stated in the press release, but the models are freely downloadable.
The partner list is the tell. Adopters named include Atom Computing, IonQ, IQM, Q-CTRL, Infleqtion, Rigetti-adjacent labs, and research groups at Harvard, Fermilab, Lawrence Berkeley, Sandia, UC Santa Barbara, University of Chicago, Cornell, USC, Yonsei, and the UK's National Physical Laboratory. That's a breadth of quantum stack (superconducting, trapped-ion, neutral-atom, photonic) signalling that the models generalize across platforms, not just to NVIDIA's own simulation targets.
Why it matters: Classical control for quantum hardware has been the real bottleneck to fault-tolerance, not physics. An open decoder that beats pyMatching meaningfully on both speed and accuracy shifts the frontier: the remaining work is manufacturing reliability and scale-up, not algorithmic novelty. NVIDIA is also telegraphing that quantum-adjacent compute is a workflow layer they intend to commoditize, the same way CUDA commoditized classical ML tooling.
Cerebras Files for IPO
On April 18, Cerebras filed for a public offering, targeting a mid-May listing. The S-1 references a prior $23B valuation from a February 2026 Series H and reports 2025 revenue of $510M on $237.8M net income (GAAP) — a profit margin that's unusual in a capital-intensive chip company and signals how much pricing power high-end AI inference has retained.
The strategic story is the >$10B deal with OpenAI that Cerebras closed earlier this year for inference capacity. CEO Andrew Feldman, quoted in TechCrunch: "Obviously, [Nvidia] didn't want to lose the fast inference business at OpenAI, and we took that from them." Cerebras also disclosed AWS as a major customer. The IPO is thus not a liquidity event for speculation — it's an institutional cap-table move to match the scale of incoming enterprise commitments.
This comes three weeks after SpaceX's confidential filing and reframes the 2026 IPO cohort: the new megacaps aren't all vertically integrated like SpaceX. They're specialist infrastructure plays (Cerebras in inference silicon, Groq in LPU, Lambda in GPU cloud) that have caught real revenue by owning a specific slice of the AI stack NVIDIA doesn't fully cover.
Why it matters: Nvidia's dominance in training is not a lock on inference. Specialized inference silicon with the right memory-bandwidth story can take material share from hyperscaler LLM workloads — and that's what $510M revenue from Cerebras demonstrates. For AI infrastructure buyers, the inference side of the 2026 budget will have more supplier optionality than any quarter in the past three years.
Boston Dynamics Integrates Gemini Robotics-ER 1.6 into Spot
On April 15, Boston Dynamics announced integration of Google DeepMind's Gemini Robotics-ER 1.6 into Spot's AI Visual Inspection (AIVI) platform. The integration is production, not a demo: the Gemini-powered AIVI-Learning system is live for customers already using Orbit (Spot's fleet-management software), and Spot can now answer open-ended questions about a facility from visual data — identifying unsecured doors, spills, hazard-sign compliance — rather than running pre-scripted inspection routines.
The significance is the deployment layer. Gemini Robotics-ER (Embodied Reasoning) is DeepMind's VLM-for-physical-reasoning line, and this is the first time it's shipped inside a commercial robotics product outside of DeepMind's own research demonstrations. It also complements Physical Intelligence's π0.7 story: π0.7 is a policy (how to act); Gemini Robotics-ER is a reasoning layer (what to notice). The two slot together cleanly.
Why it matters: Boston Dynamics customers don't need to know anything about VLMs — they just get a Spot that's suddenly more useful on Monday than it was on Friday. That's the deployment shape that compounds. Every inspection robot in the field is now, quietly, running a frontier VLM. The installed base of "AI-enabled robots in production" just ticked up by a meaningful fraction, without any new hardware shipping.
OpenAI Safety Fellowship
On April 15, OpenAI introduced the Safety Fellowship, a nine-month program running September 2026 through February 2027 for external AI safety researchers embedded inside OpenAI's safety team. The program is targeted at researchers from academia, other labs, and independent work — no prior OpenAI affiliation required. Cohort size, exact compensation, and application timeline details are on OpenAI's page; our earlier estimates of 15-20 fellows at $180-240K all-in are directional rather than official.
The context is W15's coverage of Project Glasswing and the broader safety-capability reckoning after the March Mythos code-leak. The fellowship is partly a credibility move and partly practical — external researchers bring different threat models, and nine-month embedded stints generate published output that advances the field broadly rather than staying internal. Anthropic has similar residency programs; Google and Meta are likely to follow.
Why it matters: Safety research is the highest-leverage hiring channel for frontier labs right now, and a nine-month embedded program is a way to audit cultural fit before extending permanent offers. The real metric to watch is retention — what share of fellows convert to full-time roles — which won't surface until Q1 2027.
Accenture Invests in General Robotics
On April 15 (the same day as Boston Dynamics × Gemini and the OpenAI Safety Fellowship), Accenture announced a strategic investment in General Robotics, a robotics firm building dexterous manipulation systems for unstructured warehouse and manufacturing tasks. The amount was not disclosed. The partnership combines Accenture's enterprise integration and change-management expertise with General Robotics's hardware and domain algorithms.
This is consistent with the W15 thread on NVIDIA GR00T and Tufts' neuro-symbolic robotics: the robotics stack is consolidating out of research into deployment, and the incumbents with enterprise relationships are positioning for margin. Manufacturing and logistics are the first two sectors ready for physical AI because task structure is more regular than in healthcare or finance.
Why it matters: When a $650B consulting firm puts strategic capital behind a robotics company in the same week that Boston Dynamics ships a VLM integration and Physical Intelligence releases a generalist policy, the narrative flips from "robotics is research" to "robotics is infrastructure." That's a durable TAM expansion, not a news-cycle moment.
ICLR 2026 Opens in Rio
ICLR 2026 runs April 23–27 in Rio de Janeiro. The full program is public, paper acceptances have been out since February, and this is the venue where world-model research, 4D scene representations, and large-scale VLA architectures will be positioned publicly for the year. Expect concentrated news flow across the five days: workshop keynotes, preprint drops, and partnership announcements from labs taking advantage of the conference window.
Why it matters: ICLR is where early-2026 research becomes publicly-canon. Watch the VLA, world-model, and 4D-scene sessions closely — they'll set the H2 2026 research agenda.
State AI Regulation Continues
The state patchwork continues to thicken following W15's coverage of Oregon, Idaho, Tennessee, and Colorado. Illinois has active bills on both sides of the AI-policy question — HB 5521 would restrict law-enforcement biometric surveillance, while SB3444 would shield frontier AI from mass-casualty liability — with Senate hearings running this month. Nebraska's LB 525, which requires conversational AI services to disclose non-human identity to users, advanced in early April. Maine's LD 2082 restricts AI-provided therapy or psychotherapy to licensed clinicians. National deployers face a compliance matrix that no vendor has commoditized yet.
The EU AI Act's August 2, 2026 full applicability is the largest force multiplier still ahead. Once that date hits, U.S. companies selling into the EU need certified documentation for high-risk AI systems — which pressures them into adopting similar posture domestically.
Why it matters: National AI compliance cost is rising faster than model inference cost. That quietly shifts competitive advantage toward companies with legal and compliance infrastructure over those with training data alone — a dynamic that favors incumbents over startups.
By the Numbers
- 100% — π0.7 success rate on in-distribution t-shirt/shorts folding, espresso making, and box building.
- 13% — Claude Opus 4.7 improvement over 4.6 on a 93-task coding benchmark.
- 3× — Production-grade tasks Opus 4.7 resolves on Rakuten-SWE-Bench vs. 4.6.
- 98.5% vs 54.5% — Opus 4.7 vs. Opus 4.6 on visual-acuity benchmarks.
- $5 / $25 per M tokens — Opus 4.7 pricing (unchanged from 4.6).
- 28.3% — U.S. generative AI adoption, ranked 24th globally (Stanford AI Index 2026).
- 73% vs 23% — AI expert vs. U.S. public share expecting positive AI impact on jobs.
- 31% — U.S. public trust in government to regulate AI — lowest among surveyed countries.
- 80%+ — U.S. high school and college students using AI for schoolwork.
- 2.5× faster, 3× more accurate — NVIDIA Ising Decoding vs. pyMatching on surface-code decoding.
- Days → hours — Ising Calibration speedup on quantum-processor calibration.
- $23B — Cerebras prior Series H valuation (Feb 2026), ahead of April 18 IPO filing.
- $510M / $237.8M — Cerebras 2025 GAAP revenue and net income.
- >$10B — Value of the Cerebras–OpenAI inference capacity deal.
- April 23–27 — ICLR 2026 in Rio de Janeiro.
- August 2, 2026 — EU AI Act full applicability.
What to Watch Next Week
- ICLR 2026 keynotes and poster sessions. The VLA, 4D-scene, and world-model tracks will set the H2 2026 research agenda. Watch for announcements timed to the conference window.
- Cerebras IPO roadshow. Pricing commentary from the mid-May book-building will reveal where the market actually values specialized inference silicon vs. the NVIDIA comp.
- π0.7 third-party replications. Compositional generalization claims live or die on out-of-distribution benchmarks outside PI's own test harness. Expect first replications from academic labs within 2–4 weeks.
- Claude Opus 4.7 enterprise feedback loop. Coding and vision benchmarks are published; the real test is long-running agentic production use. Watch Rakuten, customer testimonials, and the Copilot-competitor tier for first signals.
- NVIDIA Ising adoption. Which quantum computing labs announce Ising integration in production error correction first? Early adopters indicate conviction in the accuracy/speed claims; latecomers indicate ecosystem frictions.
- OpenAI Safety Fellowship application volume. Applicant pedigree (academia vs. industry) indicates how competitive the program becomes.
- Federal preemption movement. With the U.S. regulatory trust number at 31%, watch for any White House or Congressional action on federal preemption of state AI laws — that's the pressure valve for the state patchwork.
All References
- Physical Intelligence — π0.7: a Steerable Model with Emergent Capabilities — PI Blog (April 16, 2026)
- Physical Intelligence Says Its New Robot Brain Can Figure Out Tasks It Was Never Taught — TechCrunch (April 16, 2026)
- π₀: A Vision-Language-Action Flow Model for General Robot Control — Black, Driess, Finn, Levine et al. (October 2024)
- Introducing Claude Opus 4.7 — Anthropic (April 16, 2026)
- Inside the AI Index: 12 Takeaways from the 2026 Report — Stanford HAI (April 13, 2026)
- Stanford 2026 AI Index Report — Stanford HAI (April 2026)
- OpenAI Has Bought AI Personal Finance Startup Hiro — TechCrunch (April 13, 2026)
- NVIDIA Launches Ising: The World's First Open AI Models to Accelerate the Path to Useful Quantum Computers — NVIDIA News (April 14, 2026)
- AI Chip Startup Cerebras Files for IPO — TechCrunch (April 18, 2026)
- Boston Dynamics Integrates Google DeepMind's Gemini Robotics Model into Spot Inspection Platform — Robotics and Automation News (April 15, 2026)
- Introducing the OpenAI Safety Fellowship — OpenAI (April 15, 2026)
- Accenture Invests in General Robotics to Advance Physical AI-Powered Robotics in Manufacturing and Logistics — Accenture Newsroom (April 15, 2026)
- ICLR 2026: Rio de Janeiro, April 23–27 — ICLR Conference
- 4D Gaussian Frontier 2026 — Artifocial (April 16, 2026)
- 4D Gaussian Splatting Explained — Artifocial (April 17, 2026)
- Video Understanding for 3D: Temporal World Models — Artifocial (April 19, 2026)
- Notebook 00: 4D Gaussians from Scratch — Artifocial Tutorials (2026-W16)
- Notebook 01: Video-to-3D Toy Implementation — Artifocial Tutorials (2026-W16)
Stay connected:
- 📧 Subscribe to our newsletter for updates
- 📺 Watch our YouTube channel for AI news and tutorials
- 🐦 Follow us on Twitter for quick updates
- 🎥 Check us on Rumble for video content