Energy-Based World Models vs. Transformer-Based Generation: Two Competing Visions for Machine Intelligence
Trends of Energy-based World Models
W13 Trend Tutorial · Advanced (ML Practitioner) · March 2026
Research Area: World Models
Companion Notebooks — released progressively, links activated as each goes live:
| # | Notebook | Focus | Compute |
|---|---|---|---|
| 00 | 00_lewm_toy_world_model.ipynb | Toy JEPA world model from scratch — encoder, predictor, SIGReg regularization | CPU only |
| 01 | 01_jepa_latent_dynamics_planning.ipynb | Latent dynamics and planning — CEM, MPC, speed benchmarks | CPU only |
1. Why This Matters Now
Two days ago (March 23, 2026), a team led by Yann LeCun released LeWorldModel (LeWM) — the first JEPA that trains stably end-to-end from raw pixels, using only two loss terms and ~15M parameters on a single GPU. It plans up to 48× faster than foundation-model-based world models while staying competitive on diverse control tasks.
The day after (March 24), OpenAI killed Sora — shutting down its generative video platform entirely and unwinding a $1 billion deal with Disney, citing unsustainable compute costs relative to other business priorities.
These two events, 24 hours apart, crystallize the deepest architectural split in AI today. One camp — led by LeCun and backed by AMI Labs' $1.03 billion — argues that predicting abstract representations is the right way to model the physical world. The other — led by Fei-Fei Li's World Labs and backed by $1 billion including $200M from Autodesk — generates visual worlds directly.
With Sora dead and LeWM alive, the evidence is shifting. This tutorial unpacks both approaches, introduces LeWorldModel as a breakthrough proof point, and analyzes where the field is heading.
2. The Core Debate: Prediction vs. Generation
The fundamental question: how should an AI system model the physical world?
| Dimension | Energy-Based (JEPA / AMI) | Generative (Transformers / Diffusion) |
|---|---|---|
| Core operation | Predict abstract representations | Generate raw outputs (pixels, tokens) |
| What gets predicted | Latent embeddings (high-level structure) | Every detail of the output (pixel-level) |
| Handling uncertainty | Energy landscape over compatible states | Probability distribution over outputs |
| Training signal | Non-contrastive self-supervised (VICReg, Barlow Twins, SIGReg) | Next-token prediction / denoising |
| Irrelevant details | Discarded by encoder — only structure matters | Must be predicted — every pixel counts |
| Compute efficiency | LeWM: ~15M params, single GPU, hours | Sora: massive compute, so costly OpenAI shut it down |
| Primary output | Representations for reasoning and planning | Rendered content (images, video, text) |
LeCun's core argument is simple: predicting every pixel of a future video frame is both wasteful and brittle. Most pixel-level details are irrelevant to understanding what's happening in a scene. A system that reasons about the world should predict at the level of meaning, not pixels. Sora's shutdown lends this argument real weight — even OpenAI couldn't justify the compute cost of pixel-level world simulation.
3. The Energy-Based Approach: JEPA and AMI
3.1 LeCun's 2022 Blueprint
The intellectual foundation is LeCun's 2022 position paper, A Path Towards Autonomous Machine Intelligence. It proposes a cognitive architecture with six modules: perception, world model, cost, actor, short-term memory, and configurator. The world model — the centerpiece — uses JEPA to learn predictive representations of the environment.
3.2 How JEPA Works
JEPA operates through joint embeddings rather than reconstruction:
- Two encoding branches: An encoder maps input to representation ; a separate encoder maps target to . The encoders need not be identical.
- Prediction in latent space: A predictor module estimates from , optionally conditioned on a latent variable .
- Energy as prediction error: The energy function measures compatibility. Low energy means and are consistent; high energy means they're not.
- No pixel-level reconstruction: The system never tries to generate raw pixels. It learns that "a ball thrown upward will come back down" without needing to render every frame.
The latent variable is critical — it captures the information we cannot predict (stochastic elements, unobserved factors). By minimizing the information content of during training, the model learns to encode only what's predictable, discarding irrelevant noise.
3.3 The Collapse Problem (and Why JEPA Has Been Fragile)
The central challenge with JEPA has been representation collapse: the encoder learns to map everything to the same constant vector, making prediction trivially perfect but useless. Previous JEPA implementations avoided this through fragile engineering hacks — stop-gradients, exponential moving averages (EMA), multi-term losses with 6+ hyperparameters, or pre-trained frozen encoders (e.g., DINO features). These hacks worked but made JEPA impractical and difficult to reproduce.
This is what makes LeWorldModel so significant — it eliminates all of these crutches.
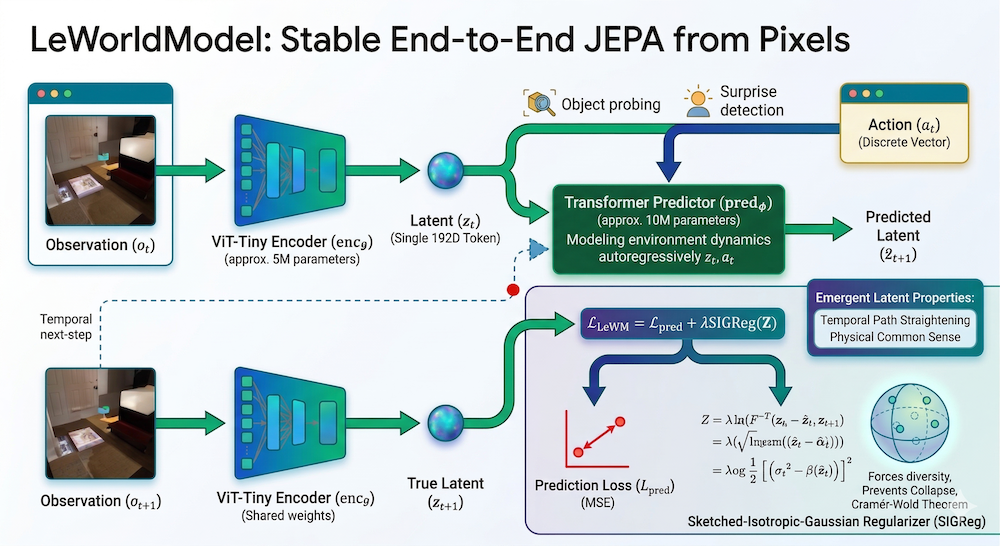
3.4 LeWorldModel: The End-to-End JEPA Breakthrough
LeWorldModel (LeWM), released March 23, 2026, by Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun, and Randall Balestriero (Mila, NYU, Samsung SAIL, Brown University), is the first JEPA that trains stably end-to-end from raw pixels with no heuristics.
Architecture:
- Encoder: ViT-Tiny (~5M parameters) — maps each frame observation into a compact, low-dimensional latent representation
- Predictor: Transformer (~10M parameters) — models environment dynamics in latent space by predicting the next frame's embedding given the current embedding and an action
- Total: ~15M parameters — trainable on a single GPU in a few hours
The Two-Term Loss:
LeWM uses only two loss terms — down from the six required by the only existing end-to-end alternative:
- MSE prediction loss: Standard mean-squared error between predicted and actual next-frame embeddings. This drives the model to learn accurate dynamics.
- SIGReg (Sketched Isotropic Gaussian Regularizer): The anti-collapse mechanism. SIGReg enforces that latent embeddings follow an isotropic Gaussian distribution.
How SIGReg prevents collapse:
SIGReg leverages the Cramér-Wold theorem: a multivariate distribution matches a target (isotropic Gaussian) if and only if all its one-dimensional projections match that target. In practice:
- Project the batch of latent embeddings onto random 1D directions
- Apply the Epps-Pulley test statistic to each 1D projection — measuring how far it deviates from a Gaussian
- Average the test statistics as the regularization loss
This is elegant because it's scalable (no pairwise covariance matrix needed), stable (statistically grounded via the Cramér-Wold theorem), and simple (one hyperparameter: the regularization weight).
Results:
| Environment | LeWM Performance | Key Comparison |
|---|---|---|
| Push-T (block manipulation) | 96% success rate | Beats DINO-WM (which uses pretrained features + proprioceptive inputs) |
| Reacher (2-joint arm) | Outperforms DINO-WM | Competitive with models using extra input modalities |
| Two-Room (2D navigation) | Strong baseline | Matches specialized methods |
| OGBench-Cube (3D pick-and-place) | Competitive | Strong on 3D control tasks |
Planning speed: <1 second, up to 48× faster than foundation-model-based world models.
Why this matters for the field:
LeWM proves that JEPA can work from raw pixels without crutches. This removes the biggest technical objection to the energy-based approach: that it required pre-trained features or fragile training procedures. With LeWM, you can train a world model from scratch, from pixels, on a single GPU, in hours, and get competitive results. The code is open-source at github.com/lucas-maes/le-wm.
3.5 From I-JEPA to V-JEPA 2: The Scaling Story
Before LeWM simplified the training, Meta's team scaled JEPA through several iterations:
I-JEPA (2023, Meta AI) applied the architecture to images. Given a partially masked image, I-JEPA predicts the representations of missing regions — not the pixels themselves.
V-JEPA (2024, Meta AI) extended this to video. By masking space-time patches and predicting their representations, V-JEPA learns temporal dynamics without ever reconstructing video frames.
V-JEPA 2 (2025, arXiv:2506.09985) scaled to 1.2B parameters trained on 1M+ hours of video with progressive resolution training:
- 77.3 top-1 accuracy on Something-Something v2 (motion understanding)
- State-of-the-art 39.7 recall@5 on Epic-Kitchens-100 (action anticipation)
- 84.0 on PerceptionTest when aligned with an LLM
- Zero-shot robotic planning: V-JEPA 2-AC deploys on Franka arms for pick-and-place using only 62 hours of unlabeled robot video — no task-specific training or reward
VL-JEPA (arXiv:2512.10942) extends the framework to vision-language, achieving stronger performance than standard VLM training with 50% fewer trainable parameters.
3.6 What AMI Labs Is Building
AMI Labs (March 2026, $1.03B seed at $3.5B pre-money valuation) is led by LeCun (co-founder), with Saining Xie as Chief Science Officer (creator of the Diffusion Transformer architecture behind Sora — an ironic pedigree given Sora's demise), Pascale Fung as Chief Research & Innovation Officer, and Michael Rabbat as VP of World Models.
AMI's systems will train on video, audio, and sensor data — not just text. The goal: world models that understand physical causality (object permanence, gravity, collisions, material properties). LeCun has described this as a long-term scientific project.
The technical bet: JEPA-style architectures, scaled with the engineering insights from LeWM's stable training, will produce representations that enable planning and reasoning in ways generative models cannot.
4. The Generative Approach: World Labs and the Post-Sora Landscape
4.1 The State of Generative World Models After Sora
OpenAI's decision to shut down Sora on March 24 was not a failure of the technology per se — Sora 2 (September 2025) could generate 60-second physically-consistent video. The failure was economic: running the video model consumed so much compute that it starved other teams, and the revenue opportunity (creative tools) couldn't justify the cost versus coding tools and enterprise customers.
This confirms a version of LeCun's critique: pixel-level world simulation is computationally expensive in a way that abstract representation prediction is not. LeWM does its planning in <1 second on a single GPU; Sora required massive GPU clusters to generate a single minute of video.
But generative world models aren't dead — they're evolving.
4.2 World Labs and Marble: The Generative Counterargument
World Labs, founded by Fei-Fei Li, represents the strongest remaining case for generative world models.
Marble (generally available since November 2025) generates persistent, editable 3D worlds from multimodal inputs — text, images, video, or coarse 3D layouts:
- 3D Gaussian splat generation: Scenes are represented as millions of semitransparent 3D Gaussians, enabling photorealistic rendering from any viewpoint
- Chisel editor: Users draw rough spatial layouts, Marble fills in visual detail — human intent at the structural level, AI generation at the detail level
- Multi-format export: Gaussian splats, triangle meshes (physics simulation), or video
- NVIDIA Isaac integration: Generated worlds can be imported into robotics simulation for agent training
4.3 AMI vs. World Labs: The $2 Billion Divergence
These two companies, each backed by ~$1 billion, represent fundamentally different bets on how AI should understand the physical world. We first covered this rivalry in our W11 blog/video post; here we deepen the comparison:
| Dimension | AMI Labs (LeCun) | World Labs (Fei-Fei Li) |
|---|---|---|
| Founded by | Yann LeCun (Turing Award, Meta FAIR) | Fei-Fei Li (ImageNet, Stanford HAI) |
| Funding | $1.03B seed (Mar 2026), $3.5B valuation | $1B total incl. $200M Autodesk (Feb 2026), $5B valuation |
| Core architecture | JEPA — joint embedding predictive architecture | Generative — diffusion + 3D Gaussian splatting |
| What it produces | Abstract representations for planning/reasoning | Visual 3D worlds you can see and navigate |
| Training data | Video, audio, sensor streams, lidar | Text, images, video, 3D layouts |
| Go-to-market | Research-first: build the right architecture, then find applications | Product-first: shipped Marble (Nov 2025), Autodesk integration |
| Target applications | Industrial, robotics, healthcare — where hallucinating physics kills | Creative tools, gaming, film, architecture, robotics sim |
| Key advantage | Compute efficiency, data efficiency, planning speed | Visual quality, immediate commercial utility |
| Key weakness | No visual output — can reason but can't render | No physical reasoning — can render but may not understand |
| Compute profile | LeWM: 15M params, 1 GPU, hours | Marble: large-scale generation infrastructure |
| Open research | V-JEPA 2, VL-JEPA, LeWM (all open-source) | No full architectural paper; commercial product |
The deepest difference: AMI is building understanding (can this robot plan a safe path?), while World Labs is building synthesis (can this tool generate the room the robot will practice in?). These may not be competing — they may be complementary layers of the same stack.
4.4 Video Foundation Models: Implicit World Models Under Pressure
With Sora dead, the remaining video world model contenders are Google's Veo 3.1 (January 2026, 4K, reference-image conditioning) and open-source projects like HunyuanVideo WorldPlay (Tencent, with RL post-training code on GitHub).
The CVPR 2025 tutorial From Video Generation to World Model mapped the frontier from passive generation toward interactive simulation. With Sora gone, the question of whether video generation can become true world modeling has lost its most prominent champion.
5. The Broader Landscape: Related Breakthroughs
5.1 R2-Dreamer: Decoder-Free World Models
Released the same week as LeWM, R2-Dreamer (March 18, 2026) proposes a decoder-free MBRL framework using a Barlow Twins-inspired redundancy-reduction objective to prevent collapse without data augmentation. On DeepMind Control Suite and Meta-World, R2-Dreamer matches DreamerV3 and TD-MPC2 while training 1.59× faster than DreamerV3.
The convergence is striking: both LeWM and R2-Dreamer independently arrived at the conclusion that world models don't need decoders or pretrained features — just the right regularization objective.
5.2 Causal-JEPA: Object-Level World Models
Causal-JEPA (February 2026) extends the JEPA framework from image patches to object-centric representations using object-level masking that induces causal inductive biases via latent interventions. Key result: ~20% absolute improvement in counterfactual reasoning, and planning with only 1% of the latent features required by patch-based world models.
5.3 Self-Improving World Models (ASIM)
From the ICLR 2026 RSI Workshop (our W12 coverage): ASIM uses cycle-consistency between forward and inverse models for architecture-agnostic self-improvement with 50%+ less data.
5.4 The RSI Connection: From Self-Improving Models to Self-Improving World Understanding
If you've been following our W10–W12 coverage, the world models story should feel structurally familiar — because the core failure modes are the same.
In our RSI weeks, we showed how self-play and self-training loops (STaR, ReST, Contextual Drag) can degrade when the model finds trivial shortcuts: a self-play proposer that generates only easy problems, a self-trainer that reward-hacks its own verifier, or a self-refining agent whose corrections compound errors rather than fixing them. The central RSI challenge is keeping the self-improvement loop honest — ensuring the model actually learns rather than exploiting the training signal.
JEPA world models face the exact same challenge, wearing different clothes. Representation collapse — where the encoder maps every input to a constant vector — is the world model equivalent of reward hacking. The model "solves" the prediction objective by making every prediction trivially correct, learning nothing useful in the process. Previous JEPA implementations required fragile hacks (stop-gradients, EMA, multi-term losses) to prevent this, just as previous self-play systems required careful curriculum design and rejection sampling to stay productive.
LeWM's SIGReg is to world model collapse what verification-based filtering is to self-training collapse: a principled regularizer that keeps the learning loop honest without human intervention. The parallel isn't just conceptual — it's mathematical. SIGReg enforces distributional structure on the latent space (Gaussianity via Cramér-Wold). Verification-based self-training enforces correctness structure on generated solutions. Both prevent degenerate convergence by constraining what the model is allowed to learn.
ASIM closes the circle: it applies self-improvement principles directly to world models via forward-inverse cycle-consistency. This is the intersection point of our entire W10–W15 arc — the question isn't just "can AI improve itself?" (RSI) or "can AI understand the world?" (world models), but can AI improve its own understanding of the world, autonomously?
For our notebooks this week, this connection matters practically: NB 00 implements SIGReg regularization in pure NumPy and shows what happens when you remove it (collapse), drawing a direct parallel to how verification filtering prevents reward hacking in W11's STaR notebook — same principle, different domain.
6. Where Each Approach Excels (and Fails)
| Capability | Energy-Based (JEPA) | Generative (Transformer/Diffusion) |
|---|---|---|
| Physical reasoning | Strong — learns causal structure in latent space | Weak — approximates appearance of physics |
| Planning speed | LeWM: <1 sec, 48× faster than foundation models | Slow — generation is the bottleneck |
| Visual generation quality | Not designed for generation — produces representations, not images | Excellent — state-of-the-art photorealism (but expensive) |
| Data efficiency | High — V-JEPA 2 does zero-shot robotics from 62hr unlabeled video | Low — requires massive datasets for each domain |
| Compute efficiency | LeWM: 15M params, 1 GPU, hours; V-JEPA 2: 1.2B, still tractable | Sora: so costly OpenAI shut it down |
| Robotics applications | Direct — latent predictions feed into controllers | Indirect — Marble generates sim environments; no direct control |
| Creative applications | Limited — cannot render visual content | Excellent — gaming, film, design, architecture |
| Training stability | Solved — LeWM trains end-to-end with 1 hyperparameter | Stable but requires massive scale |
| Scalability evidence | LeWM (15M) → V-JEPA 2 (1.2B) — proven at both scales | GPT-4V, Veo at hundreds of billions — proven at scale |
7. The Hybrid Thesis and the Engineering Angle
For Practitioners: What Can You Build Today?
The LeWM release is particularly exciting for researchers and engineers with limited compute — exactly our situation. With 15M parameters and single-GPU training, this is within reach for anyone with a consumer-grade GPU. The code depends on stable-worldmodel for environment management, planning, and evaluation, and stable-pretraining for training infrastructure.
The key insight for small teams: you don't need foundation-scale compute to do meaningful world model research. LeWM beats DINO-WM (which uses pretrained DINOv2 features) on Push-T with only raw pixel input and a fraction of the parameters. This validates our approach from previous weeks — finding the engineering sweet spots where small-scale work can produce frontier-competitive results.
The Convergence Signal
Several developments suggest convergence rather than winner-take-all:
- LeWM + R2-Dreamer independently show that decoder-free, regularization-based training is the path forward for efficient world models
- V-JEPA 2's LLM alignment shows JEPA representations can connect to language models for multimodal reasoning
- Marble's simulation integration (NVIDIA Isaac) means even generative world models serve planning use cases
- Causal-JEPA adds object-level reasoning to the JEPA framework, bridging toward richer world understanding
The most likely trajectory: energy-based encoders for perception and planning, generative decoders for rendering and content creation, connected through a shared latent space. AMI and World Labs may end up as complementary layers rather than competitors.
8. What to Watch
-
LeWM scaling experiments. At 15M parameters, LeWM is competitive. What happens at 100M? 1B? The scaling behavior of end-to-end JEPA world models is uncharted territory — and with stable training now solved, the experiments are feasible.
-
AMI's first technical results. With $1B, Saining Xie, and the LeWM training recipe, expect AMI's first publications within 6–12 months. Will they build on LeWM's SIGReg approach or develop new stabilization methods?
-
Post-Sora generative landscape. With OpenAI out, Google's Veo and open-source projects (HunyuanVideo, LTX, Helios) become the generative world model frontier. Will any of them cross the interactive threshold?
-
World Labs' robotics pipeline. Marble + Isaac Sim is the generative camp's strongest argument for practical world models. Sim-to-real transfer results will be definitive.
-
Notebook 00 this week. We reproduce LeWM's core training loop at minimal scale — a pure NumPy MLP encoder + predictor with SIGReg regularization, trained from raw pixels on BallWorld. No PyTorch, no autograd — every gradient is hand-derived. Trains on any laptop CPU in under 2 minutes.
References
Key Papers
- LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels — Maes, Le Lidec, Scieur, LeCun, Balestriero (2026) ← NEW
- R2-Dreamer: Redundancy-Reduced World Models without Decoders or Augmentation — Morihira et al. (2026) ← NEW
- Causal-JEPA: Learning World Models through Object-Level Latent Interventions — Nam et al. (2026) ← NEW
- A Path Towards Autonomous Machine Intelligence — LeCun (2022)
- I-JEPA: Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture — Assran et al. (2023)
- V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning — Bardes et al. (2025)
- VL-JEPA: Joint Embedding Predictive Architecture for Vision-Language — Meta (2025)
- Attention Is All You Need — Vaswani et al. (2017)
Companies and Products
- AMI Labs — LeCun's world model startup ($1.03B seed)
- World Labs / Marble — Fei-Fei Li's spatial intelligence world model
- OpenAI Discontinues Sora — Variety (March 24, 2026)
Code
- LeWM GitHub Repository — Official code, trainable on single GPU
- Our NB 00: Toy World Model — Pure NumPy reproduction of LeWM's core ideas (CPU, ~2 min)
- V-JEPA GitHub Repository — Meta's open-source implementation
- HunyuanVideo WorldPlay — RL post-training for interactive video world models
Surveys and Resources
- Understanding World or Predicting Future? A Comprehensive Survey of World Models — ACM Computing Surveys (2025)
- From Video Generation to World Model — CVPR 2025 Tutorial
Stay connected:
- 📧 Subscribe to our newsletter for updates
- 📺 Watch our YouTube channel for AI news and tutorials
- 🐦 Follow us on Twitter for quick updates
- 🎥 Check us on Rumble for video content