Self-Play in AI: From Board Games to Language Models
With LLMs, when self-play works and when it doesn't.
W11 Basic Tutorial (Beginner) · No prerequisites beyond basic ML familiarity · March 2026
Companion Notebook:
01_self_play_fundamentals.ipynb— Requires GPU (T4 or better), ~90 min runtime
What is Self-Play?
Self-play is a training technique where an AI system improves by competing or interacting with copies of itself. Instead of learning from human-generated data or human feedback, the system generates its own training signal through this self-interaction.
Think of it like a chess player who practices by playing against themselves. Each game produces new situations to learn from, and as the player improves, the games get harder — creating a natural learning curriculum.
A Brief History
Games: Where It All Started
Self-play's first major success was in board games:
TD-Gammon (1992) — Gerald Tesauro at IBM built a backgammon AI that played millions of games against itself. Starting from random play, it reached world-class level. This was remarkable because nobody programmed backgammon strategy into it — the strategy emerged from self-play.
AlphaGo (2016) — DeepMind's Go-playing AI used self-play as a key ingredient. After initially learning from human expert games, it then played millions of games against itself to surpass human ability.
AlphaZero (2017) — The breakthrough: AlphaZero learned chess, Go, and shogi from scratch using only self-play. No human games, no hand-crafted rules — just the rules of the game and self-play. It defeated the world's strongest chess engine (Stockfish) after just 4 hours of training.
Why Games Were Easy (Relatively)
Games have properties that make self-play straightforward:
- Clear rules: The game defines exactly what moves are legal
- Unambiguous outcomes: You win, lose, or draw — no gray area
- Perfect verification: The game itself tells you who won
- Closed environment: Nothing outside the game board matters
These properties mean the "training signal" (did I win or lose?) is always available and always reliable.
The Language Model Challenge
Now consider applying self-play to a language model. You want the model to improve at, say, writing code or solving math problems by "playing against itself."
Immediately, you hit problems:
No clear winning condition. In chess, checkmate is checkmate. In language generation, what counts as a "better" response? Who decides?
Verification is hard. A chess engine can instantly check if a move is legal and if the game is won. Checking if a piece of code is correct, or if a math proof is valid, requires a separate evaluator — and that evaluator might itself be unreliable.
Degenerate solutions. A language model "playing against itself" might learn to produce outputs that score well on some metric but are actually nonsensical — similar to how GANs can suffer from mode collapse.
How Self-Play Works for LLMs
Despite these challenges, researchers have found ways to make self-play work for language models. The key idea: create a game-like structure around language generation.
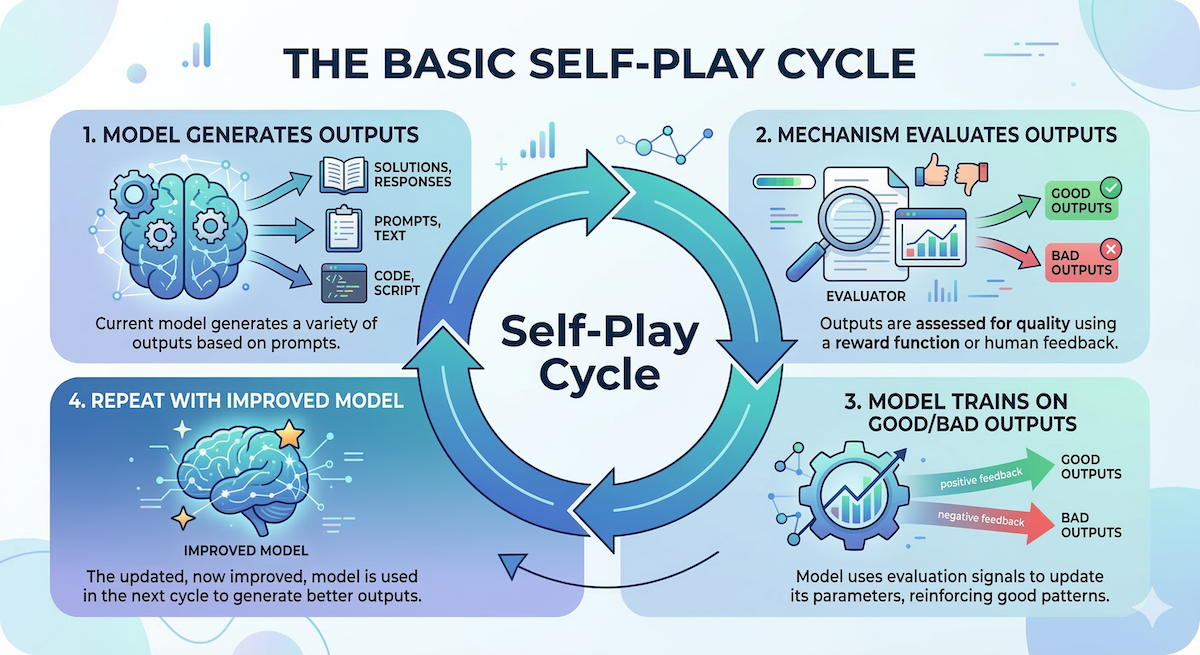
The Basic Loop
1. Model generates outputs (solutions, responses, code)
2. Some mechanism evaluates those outputs
3. Model trains on the good outputs (and learns to avoid bad ones)
4. Repeat with the now-improved modelThis looks simple, but step 2 — evaluation — is where all the complexity lives.
Three Approaches to Evaluation
Approach 1: External Verifier Use an external tool to check correctness. For code, run test cases. For math, check against known answers. This is the most reliable approach but only works in domains where you can verify outputs programmatically.
Approach 2: Self-Evaluation The model evaluates its own outputs. "Is this response better than that one?" This is cheaper but risky — the model might have blind spots that persist across iterations.
Approach 3: Adversarial Self-Play Train two copies of the model: one generates outputs, the other tries to distinguish generated outputs from reference (human-written) outputs. This is similar to how GANs work. Recent research (February 2026) has shown this is mathematically equivalent to a well-studied technique called adversarial imitation learning.
A Concrete Example: Self-Play for Math
Here's how self-play works in practice for mathematical reasoning:
Iteration 0: Model can solve 30% of math problems correctly
Iteration 1:
- Model generates 1000 attempts at various math problems
- Verifier checks which are correct (300 correct, 700 wrong)
- Model fine-tunes on the 300 correct solutions
- Model can now solve 38% of problems
Iteration 2:
- Improved model generates 1000 new attempts
- Verifier checks (380 correct, 620 wrong)
- Model fine-tunes on the 380 correct solutions
- Model can now solve 45% of problems
... and so onEach iteration, the model trains on its own successful outputs, gradually improving. The key insight: the model doesn't need new human data — it generates its own training data and filters it through verification.
Why Self-Play Matters
Reduced Data Dependency
Traditional fine-tuning requires expensive human annotations. Self-play generates training signal from the model itself, dramatically reducing the need for human labor.
Emergent Curriculum
As the model improves, the problems it can solve get harder, and the training data it generates naturally shifts toward more challenging examples. This creates an automatic curriculum — no need to manually design a progression of difficulty.
Scalability
Self-play can run indefinitely. As long as the model keeps improving (and the verification remains reliable), you can keep generating new training data. This is a path toward continuous improvement without continuous human effort.
Connection to Recursive Self-Improvement
Self-play is one of the most concrete, working examples of recursive self-improvement in AI. The model improves itself, which produces better training data, which improves the model further. Understanding self-play is foundational for understanding the broader RSI landscape.
Limitations and Open Problems
Verification bottleneck. Self-play is only as good as the verification mechanism. In domains where we can't reliably check outputs (creative writing, open-ended reasoning), self-play is much harder to apply.
Plateaus. Models eventually stop improving through self-play alone. When the model can solve everything the Proposer generates, there's no learning signal left. Breaking through plateaus is an active research problem.
Distribution shift. Each iteration of self-play changes the model's output distribution. If not managed carefully, the model can drift into regions where it generates fluent-sounding but incorrect outputs.
Safety. A self-improving system that doesn't require human-in-the-loop raises alignment questions. How do we ensure the model improves in directions we actually want?
Key Takeaways
- Self-play = training by interacting with yourself, generating your own learning signal
- It revolutionized game-playing AI (AlphaZero) and is now being adapted for language models
- The main challenge is verification — games have clear win conditions, language doesn't
- Recent work (Feb 2026) formalizes when self-play works (learnable information gain) and why (adversarial imitation learning equivalence)
- Self-play is a concrete, working form of recursive self-improvement — the AI gets better, generates better data, and gets better still
Further Reading
- AlphaZero: Shedding new light on chess, shogi, and Go — DeepMind's original AlphaZero blog post
- SPIN: Self-Play Fine-Tuning — The foundational paper on self-play for LLMs
- This week's trend tutorial on the Proposer/Solver/Verifier framework — for the advanced treatment of where self-play research stands in 2026
Stay connected:
- 📧 Subscribe to our newsletter for updates
- 📺 Watch our YouTube channel for AI news and tutorials
- 🐦 Follow us on Twitter for quick updates
- 🎥 Check us on Rumble for video content