Self-Training Loops for LLMs: STaR and the Self-Instruct Family
How to filter for correctness, not just fluency
W11 Basic Tutorial (Intermediate) | Prerequisites: familiarity with fine-tuning, RLHF basics, and transformer architectures | March 2026
Companion Notebook:
02_self_training_star_rest.ipynb— STaR implementation with engineering callouts, Colab free tier (~5-7 hours)
Introduction
Self-training — where a model improves by training on its own outputs — has evolved from a simple semi-supervised learning trick into a family of sophisticated methods that form the backbone of modern LLM improvement pipelines. This tutorial traces the lineage from Self-Instruct through STaR to the latest 2026 variants, with emphasis on the practical engineering decisions behind each method. EM is one of the most underappreciated algorithms in ML, and ReST-EM — which frames self-training as expectation-maximization — deserves the full treatment. We cover it in a dedicated upcoming tutorial that traces EM from classical foundations to modern LLM self-training.
1. The Self-Training Paradigm
The basic self-training recipe for LLMs is:
while model improves:
1. Generate: model produces candidate outputs for a set of problems
2. Filter: select high-quality outputs using some criterion
3. Train: fine-tune the model on the selected outputsEvery method in this family is a variation on these three steps. The variations differ in how they generate, what they filter on, and how they train.
Why It Works (Intuitively)
Consider a model that can solve 40% of math problems. When it generates 100 attempts:
- ~40 will be correct (the model already knows how to solve these)
- ~60 will be wrong
If we filter to keep only the correct solutions and fine-tune, we're effectively distilling the model's best behavior into a new version. The new model has seen more examples of its own correct reasoning patterns, making it more likely to apply them consistently.
The counterintuitive part: the model is teaching itself things it already "knows" but doesn't reliably execute. Self-training converts unreliable capabilities into reliable ones.
2. Self-Instruct (2022)
Paper: Self-Instruct: Aligning Language Models with Self-Generated Instructions
Self-Instruct was the first widely-adopted method for bootstrapping instruction-following capability without human annotations at scale.
How It Works
# Pseudocode for Self-Instruct
seed_tasks = load_human_written_seed_tasks(175) # small seed set
for iteration in range(many):
# Step 1: Generate new task instructions
new_instruction = LLM.generate(
prompt=f"Given these example tasks: {sample(seed_tasks, 8)}, "
f"write a new, different task instruction."
)
# Step 2: Classify as generation or classification task
task_type = LLM.classify(new_instruction)
# Step 3: Generate input-output instances
if task_type == "generation":
instance = LLM.generate(input_for=new_instruction)
else:
instance = LLM.generate(input_output_for=new_instruction)
# Step 4: Filter low-quality instances
if passes_quality_filters(instance):
training_data.append(instance)
# Fine-tune base model on collected data
fine_tuned_model = train(base_model, training_data)Key Design Decisions
- Seed set: Only 175 human-written tasks. The LLM generates everything else.
- Diversity filtering: ROUGE-L similarity check ensures new instructions differ from existing ones
- Quality filtering: Heuristic rules (no "image" or "picture" references for text-only models, length constraints)
- Scale: Generated ~52K instructions and ~82K instances from GPT-3
Impact and Limitations
Self-Instruct launched the entire synthetic data movement for LLM alignment. Stanford's Alpaca model used this method to fine-tune LLaMA and produce a ChatGPT-like model for under $600.
Key limitation: No verification of output correctness. The filter is heuristic, not semantic. If the base model generates a wrong answer confidently, it enters the training set.
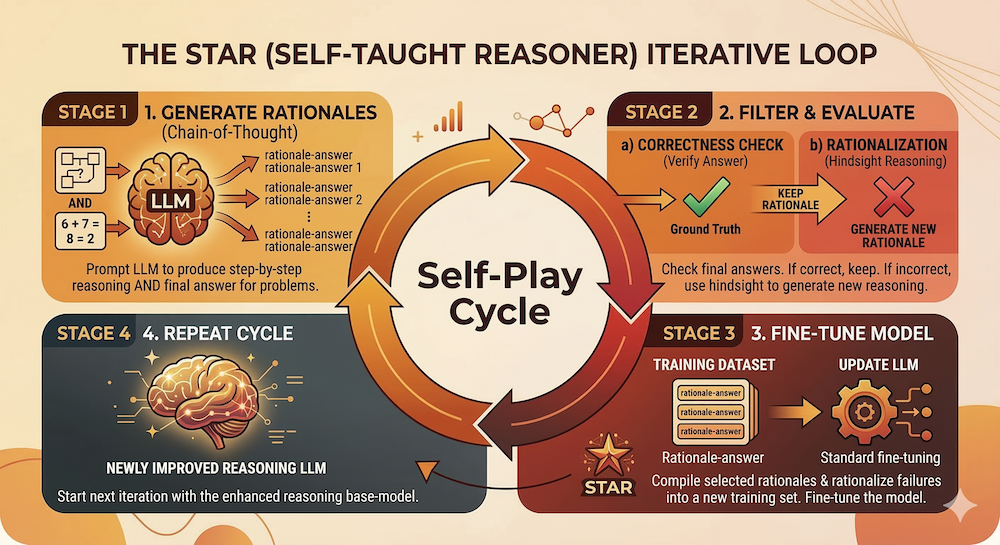
3. STaR: Self-Taught Reasoner (2022)
Paper: STaR: Bootstrapping Reasoning with Reasoning
STaR addressed Self-Instruct's key limitation for reasoning tasks: how do you filter for correctness, not just fluency?
How It Works
# Pseudocode for STaR
dataset = load_QA_dataset() # questions with known answers
for iteration in range(N):
correct_rationales = []
for question, answer in dataset:
# Step 1: Generate rationale + answer
rationale, predicted_answer = model.generate(
prompt=f"Q: {question}\nLet's think step by step..."
)
# Step 2: Filter by answer correctness
if predicted_answer == answer:
correct_rationales.append((question, rationale, answer))
else:
# Step 3: "Rationalization" — generate with answer hint
rationalized = model.generate(
prompt=f"Q: {question}\nThe answer is {answer}. "
f"Let's explain why step by step..."
)
correct_rationales.append((question, rationalized, answer))
# Step 4: Fine-tune on correct rationales
model = fine_tune(model, correct_rationales)The Key Innovation: Rationalization
When the model gets an answer wrong, STaR doesn't just discard it. Instead, it provides the correct answer as a hint and asks the model to rationalize — generate a reasoning chain that leads to the correct answer. This dramatically increases the amount of usable training data per iteration.
Why Rationalization Works
Rationalization exploits the gap between a model's generation ability (what it can produce from scratch) and its conditional generation ability (what it can produce given a hint). A model that can't solve a problem independently might still generate a valid reasoning chain when given the answer — and training on that chain teaches the model to arrive at the answer independently next time.
Limitations
- Requires verifiable answers: STaR needs ground-truth answers to filter on. This limits it to tasks where correctness is checkable (math, factual QA, code with tests).
- Rationalization quality: Rationalized chains aren't always faithful — the model might generate plausible-sounding but logically flawed reasoning that happens to reach the correct answer.
- Plateau: After several iterations, the model solves most problems it can rationalize, and improvement slows.
4. ReST-EM and Beyond (Preview)
Paper: ReST: Reinforced Self-Training
Where STaR uses rationalization to recover from failures, ReST takes a different approach: generate K candidate solutions per problem, keep the correct ones (Grow/E-step), and fine-tune on the filtered set (Improve/M-step). This is self-training framed as expectation-maximization, and that framing is more than cosmetic — it connects LLM self-training to a deep lineage in machine learning: K-means, Gaussian mixtures, HMMs, topic models, and variational inference all follow the same E-step/M-step pattern.
EM is one of the most underappreciated algorithms in ML, and ReST-EM deserves the full treatment it rarely gets. We cover it in a dedicated upcoming tutorial that builds EM intuition from classical foundations, implements it from scratch on toy problems, and then shows how ReST-EM is the same algorithm operating at LLM scale. This includes ReST-MCTS* (THUDM, NeurIPS 2024), which integrates Monte Carlo Tree Search with process reward models into the Grow step for higher-quality reasoning traces.
In this series: The EM Algorithm — From Classical Foundations to LLM Self-Training
5. The 2026 Landscape: What's New
Video-STaR (2026)
Extends STaR to multimodal settings. A vision-language model:
- Generates video understanding instructions
- Fine-tunes on its own successful instruction-following
- Repeats
This is directly relevant to multimodal foundation model research — it shows self-training loops work across modalities, not just text.
CARE-STaR (ACL 2025)
Addresses a practical failure mode: data quality degradation across iterations. Standard STaR accumulates errors because rationalized chains aren't always correct. CARE-STaR adds constraint-awareness — the model checks whether its reasoning satisfies known constraints before including it in the training set.
Generative Self-Refinement (GSR, 2026)
GSR-7B demonstrates that self-refinement (generate → critique → revise) can outperform Best-of-N sampling on the hardest math benchmarks (AIME, Olympiad). The key finding: self-refinement shines precisely on problems where all initial candidates fail — it can find solutions that pure sampling cannot.
6. Practical Decision Guide
When choosing a self-training method for your own work:
| Scenario | Recommended Method | Why |
|---|---|---|
| Instruction-following, no ground truth | Self-Instruct | Only option when answers can't be verified |
| Reasoning tasks with verifiable answers | STaR or ReST | Ground truth enables reliable filtering |
| Hard problems, need high-quality traces | ReST-MCTS* | Process rewards + tree search find better reasoning paths |
| Multimodal tasks | Video-STaR pattern | Adapts self-training to vision-language settings |
| Need improvement on hardest problems | GSR (self-refinement) | Critique-and-revise finds solutions that sampling misses |
Model-Task Pairing: The Most Underrated Decision
Choosing the right self-training method gets all the attention. Choosing the right model-task pairing is what actually determines whether self-training works at all.
The core insight comes from educational psychology: Vygotsky's Zone of Proximal Development (ZPD). Learning happens in the zone between what a learner can do independently and what they can do with scaffolding. Below this zone, scaffolding doesn't help — the gap is too wide. Above it, there's nothing new to learn.
For self-training, "scaffolding" is rationalization (STaR) or multi-sample filtering (ReST). The model needs enough base capability to produce some correct reasoning when guided, but not so much that it already solves everything.
A case study from our companion notebook: We initially ran STaR on GSM8K (grade-school math) with Qwen2.5-3B at 4-bit quantization. Base accuracy: 22%. After 3 fully-debugged STaR iterations — correct weight sync, aligned prompt formats, completion-only loss — accuracy went nowhere: 22% → 23% → 17% → 20%. The model simply didn't have enough latent math reasoning for rationalization to work. Its rationalized chains were plausible-sounding but logically broken.
Same model, same code, same hyperparameters on ARC-Challenge (multiple-choice science reasoning). Base accuracy: 66%. After 3 iterations: 75%. The only change was the task.
This has direct implications for model-size selection. With families like Qwen2.5 (0.5B / 1.5B / 3B / 7B / 14B / 32B / 72B), Llama 3.x (1B / 3B / 8B / 70B), and Phi-3.5 (mini / small / medium), you're not choosing "the best model" — you're choosing the model that puts your target task in the ZPD:
| Model Size (4-bit) | GSM8K Expected | ARC-Challenge Expected | MMLU Expected |
|---|---|---|---|
| 0.5–1.5B | ~5–10% (below ZPD) | ~30–40% (lower ZPD) | ~25–35% (below ZPD) |
| 3B | ~20–25% (below ZPD) | ~55–70% (sweet spot) | ~45–55% (sweet spot) |
| 7–8B | ~40–55% (sweet spot) | ~75–85% (upper ZPD) | ~60–70% (sweet spot) |
| 14B+ | ~60–75% (sweet spot) | ~85%+ (above ZPD) | ~70–80% (upper ZPD) |
The table reads: if you have 3B-class hardware budget, don't force GSM8K — pick a task where the model starts at 45–75%. If your task must be GSM8K, you need at least a 7B model. Self-training amplifies existing capability; it can't create capability from nothing.
The practical check takes 2 minutes:
base_acc = evaluate(model, task, split="test[:200]")
if base_acc < 0.25:
print("Below ZPD — scale up model or scale down task")
elif base_acc > 0.75:
print("Above ZPD — diminishing returns likely")
else:
print(f"In ZPD at {base_acc:.0%} — proceed with self-training")Run this before committing GPU hours to a self-training loop. It's the highest-ROI check in your entire pipeline.
Engineering Considerations
- Compute budget: ReST-MCTS* is 5-10x more expensive per iteration than vanilla STaR due to tree search, but produces higher quality data
- Verifier quality: The ceiling of any self-training method is determined by verifier accuracy. Invest in verification first.
- Iteration count: Typically 3-5 iterations of self-training give most of the gains. Beyond 5, diminishing returns are common.
- Data mixing: Mixing self-generated data with original training data (and decaying the self-generated proportion) helps prevent distribution drift.
7. Connection to This Week's Trend
The self-training methods covered here are the foundational building blocks for the self-play approaches covered in this week's trend tutorial. Specifically:
- STaR's rationalization → becomes the Solver role in the Proposer/Solver/Verifier framework
- The generate-filter-train loop → maps directly to the self-play training cycle
- The verification challenge → directly motivates the Verifier role and the adversarial imitation approach
- ReST-EM's Grow/Improve loop (covered in a dedicated upcoming tutorial) → provides the EM-theoretic foundation for why these loops converge
Understanding this lineage makes the February 2026 self-play papers much more concrete: they're the theoretical formalization of patterns practitioners have been using since 2022.
References
- Self-Instruct: Aligning Language Models with Self-Generated Instructions (2022)
- STaR: Bootstrapping Reasoning with Reasoning (2022)
- ReST: Reinforced Self-Training (2023)
- ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search (NeurIPS 2024)
- Video-STaR: Self-Training Enables Video Instruction Tuning (ICLR 2025)
- CARE-STaR: Constraint-aware Self-taught Reasoner (ACL 2025)
- This week's trend tutorial on the Proposer/Solver/Verifier framework — for the advanced treatment of where self-play research stands in 2026
Stay connected:
- 📧 Subscribe to our newsletter for updates
- 📺 Watch our YouTube channel for AI news and tutorials
- 🐦 Follow us on X for quick updates
- 🎥 Check us on Rumble for video content